
Basic configuration of rule chains
Table of Contents:
- 1.About rule chains
- 2.Rule chain creation
- 3.Rule chain modification
- 4.Rule chain deletion
- 5.Rule chain configuration
- 6.About Nodes
1.About rule chains
The system provides a rule chain library for developers to configure message transformation, filtering, computation, and transmission on their own.
2.Rule chain creation
The system provides a default root rule chain that supports user use. No changes are made on the root rule chain, but the root rule chain is exported and re imported, and then modified and configured in the newly imported rule chain.
Firstly, follow the steps below to export the root rule chain. After clicking on export, the system will automatically download it, and the exported file will be in JSON format.

Re import the exported configuration into the system. After clicking on import, the system will directly jump to the configuration page of the newly imported rule chain. Simply click on the "Apply Change" button in the bottom right corner.
Re exit to the rule chain library menu to see the newly imported rule chain library configuration.
 4
4

3.Rule chain modification
Follow the steps below to modify the basic information of the rule chain. You can rename the rule chain imported in the previous section.



4.Rule chain deletion
You can delete a newly created rule chain by following the following steps.
note: the default root rule chain provided by the system cannot be deleted.

5.Rule chain configuration
If you need to configure the rule chain, you need to follow the following steps to enter the configuration page of the rule chain.




Next, we will explain the configuration of rule nodes that may be commonly used in different classes to manipulate data. As the default device configuration was applied in the creation of the previous device ,
the rule chain used in the default device configuration is the Root Rule Chain. Therefore, the following demonstrations are all configurations made in the Root Rule Chain.
6.About Nodes
6.1 filter
6.1.1 check fidles presence
This rule node is used to verify the existence of certain attributes in the message body or metadata, and distribute the message based on the verification results. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Message field names: The name of the attribute to be verified in the message body, which is the content of the message actively sent by the device. Multiple attributes can be configured here, and after entering each attribute, press' Enter 'to enter;
- Metadata field names: The attribute names that need to be validated in the message metadata. The metadata is the data attached to the system and generally includes three metadata attributes: DeviceType, DeviceName, and ts. Multiple attributes can be configured here, and after entering each attribute, press' Enter 'to enter;
- Check that all specified fields are present: Select the box, and when performing the above attribute verification, connect each verification condition with "and"; When not selected, during the above attribute verification, each verification condition is connected by "or";
- Explanation: Non mandatory field, additional explanation;
According to the judgment result, there are two types of exits for this rule node: true and false.
A simple usage example is as follows:

6.1.2 script
This rule node allows developers to implement data filtering through programming, that is, to distribute messages using custom filtering rules. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Function Filter: Code (customizing filtering rules through code), the function parameters include msg (message), metadata (metadata), msgType (message type pushed by the previous node), and the return value should be a Boolean value;
- Explanation: Non mandatory field, additional explanation;
According to the code logic, there are two types of exits for this rule node: true and false.
A simple usage example is as follows:

6.1.3 switch
This rule node allows developers to implement data grouping filtering through programming, that is, to distribute data using custom distribution rules. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Function Switch: Code (customizing grouping rules through code), function parameters include msg (message), metadata (metadata), msgType (message type pushed by the previous node), return value should be a string array, indicating the path to be distributed;
- Explanation: Non mandatory field, additional explanation;
According to the code logic, the exit of this rule node is defined by the coding personnel, as shown in the example.
A simple usage example is as follows
return ['High temperature'];
} else if (msg.temperature < 18) {
return ['Low temperature'];
} else {
return ['Normal temperature'];
}
The above code defines three exits, namely High temperature, Low temperature, and Normal temperature. Therefore, when connecting to the next node, we need to customize the connection according to our defined exit path, as shown in the following figure. After completing the input, press "Enter" to create a link label, and then click "Add".


6.2 properties
6.2.1 calculate delta
This rule node is used to calculate the difference between the data in this message and the corresponding data in the previous message, and to refine and distribute the message content based on the calculation results. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Input value Key: required field, the name of the attribute to be incrementally calculated;
- Output value Key: required field, the attribute name of the incremental value calculated and added to the message body;
- Decimals: Accuracy of incremental computation;
- Use cache: Select option to store the value of the previous data in memory, checked by default;
- Tell Failure if delta is negative: Select option. If the increment value is negative, it is considered a message processing failure and is checked by default;
- Add period between messages: Select option to add the time difference from the previous message in the message body, not checked by default. After selecting, you need to fill in the Period value key as the attribute name added to the message body as the calculated time difference;
- Exclude zero deltas from outbound message:Only output data with delta difference non-zero.
- Explanation: Non mandatory field, additional explanation;
According to the running results, there are three types of exits for this rule node: Success, Failure, and Other:
- Success: The data export for successful incremental calculation;
- Failure: The data exit for message processing failure. If Tell Failure if delta is negative is checked, the data with a negative increment will be calculated and output from this exit;
- Other: The data export for the attribute value to be incrementally calculated is missing from the message;
A simple usage example is as follows:

6.2.2 customer attributes
This rule node is used to add some attributes configured for users to the metadata of messages and distribute data based on the processing results. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Latest telemetry: a selection option that will retrieve the latest attribute values reported remotely by the client based on the configured key. Unchecking it will query the server attributes of the client to which the device belongs, and it will be unchecked by default;
- Source telemetry key: input item, the name of the customer attribute to be added to the message metadata;
- Target attribute: Input item, the attribute name to be added to the message metadata, which appears in conjunction with the Source telemetry key and can add multiple pairs of attributes;
- Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure. When the customer to which the device belongs is not configured, data is output from the Failure exit.
This involves setting user attributes, which can be configured as follows.

A simple example of using this rule node is as follows:

6.2.3 customer details
This rule node is used to add some detailed information configured for users to the message and distribute data based on the processing results. The configuration content of this node includes:
- Name: required field, indicating the name of the node;
- Select entity details: Multiple options, select the detailed information of the customer to be added to the message (the information configured when creating the customer, including country, city, address, email, etc.), and the attribute name format of the added information is "customer-specific content name";
- Add selected details to message metadata: If checked, the corresponding information will be added to the metadata and passed to downstream nodes; If not checked, the corresponding information will be added to the data and passed to downstream nodes. Not selected by default;
- Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure. When the customer to which the device belongs is not configured, data is output from the Failure exit.
A simple usage example is as follows:

6.2.4 tenant attributes
6.2.5 tenant details
This rule node is used to add some detailed information configured for tenants to the message and distribute data based on the processing results. The configuration content of this node is exactly the same as that of the customer details rule node, and will not be repeated here.
A simple usage example is as follows:

6.2.6 fetch device credentials
This node is used to add the device's key and token type to the message and pass it to downstream nodes. The node configuration includes:
Name: required field, indicating the name of the node;
Retrieve credentials to metadata: Select the option and add the device key information to the metadata. Otherwise, add it to the message data and select it by default;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
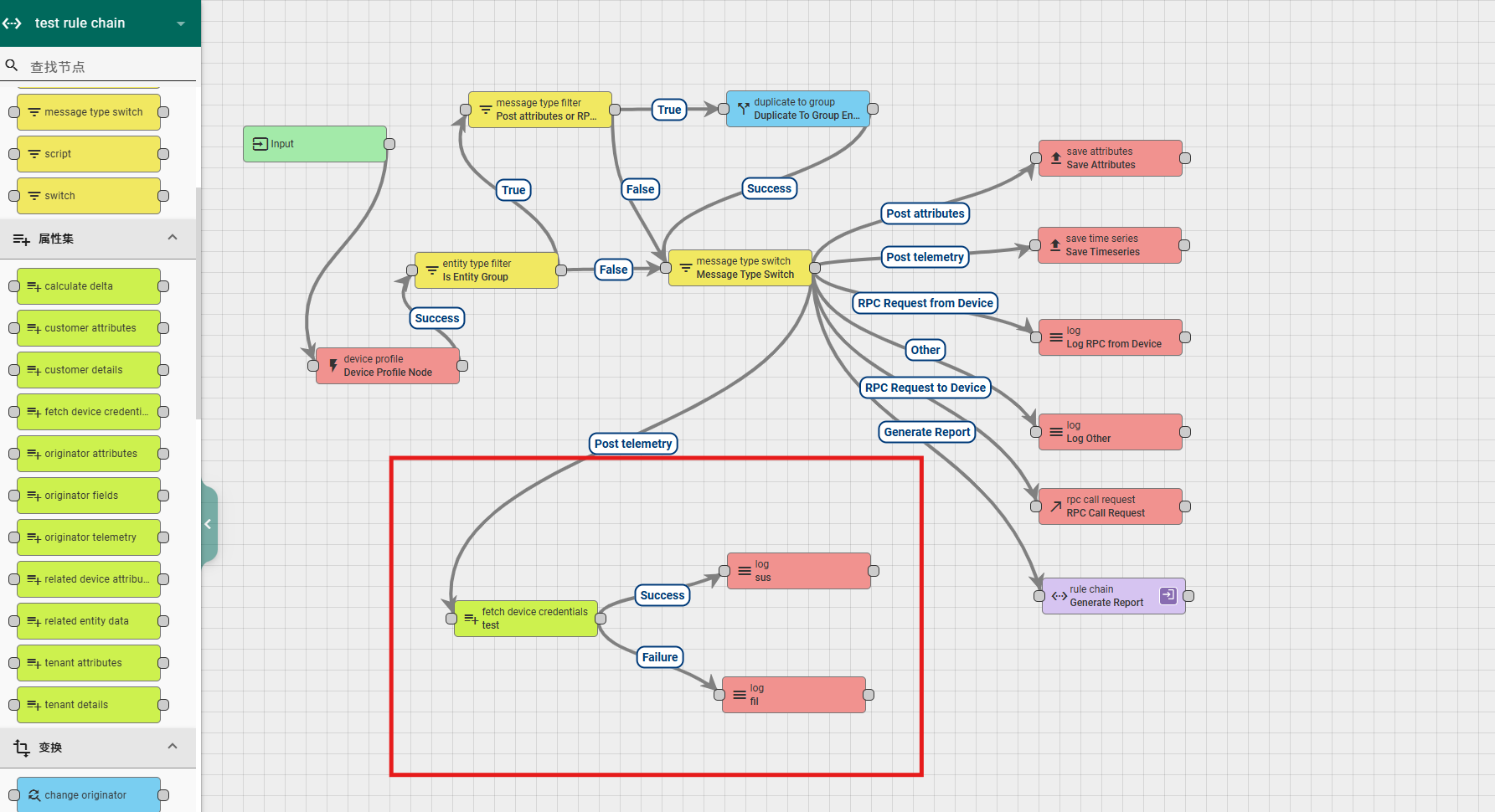
6.3 transformation
6.3.1 copy key-value pairs
This node is used to copy key values from metadata to data, or to copy key values from data to metadata. The node configuration includes:
Name: required field, indicating the name of the node;
Copy from: a selection option that allows you to choose the direction of copying, from data to metadata or from metadata to data.
The following input boxes allow you to enter the name of the attribute to be copied, and you can enter multiple names. After entering, press Enter to complete the typing once;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
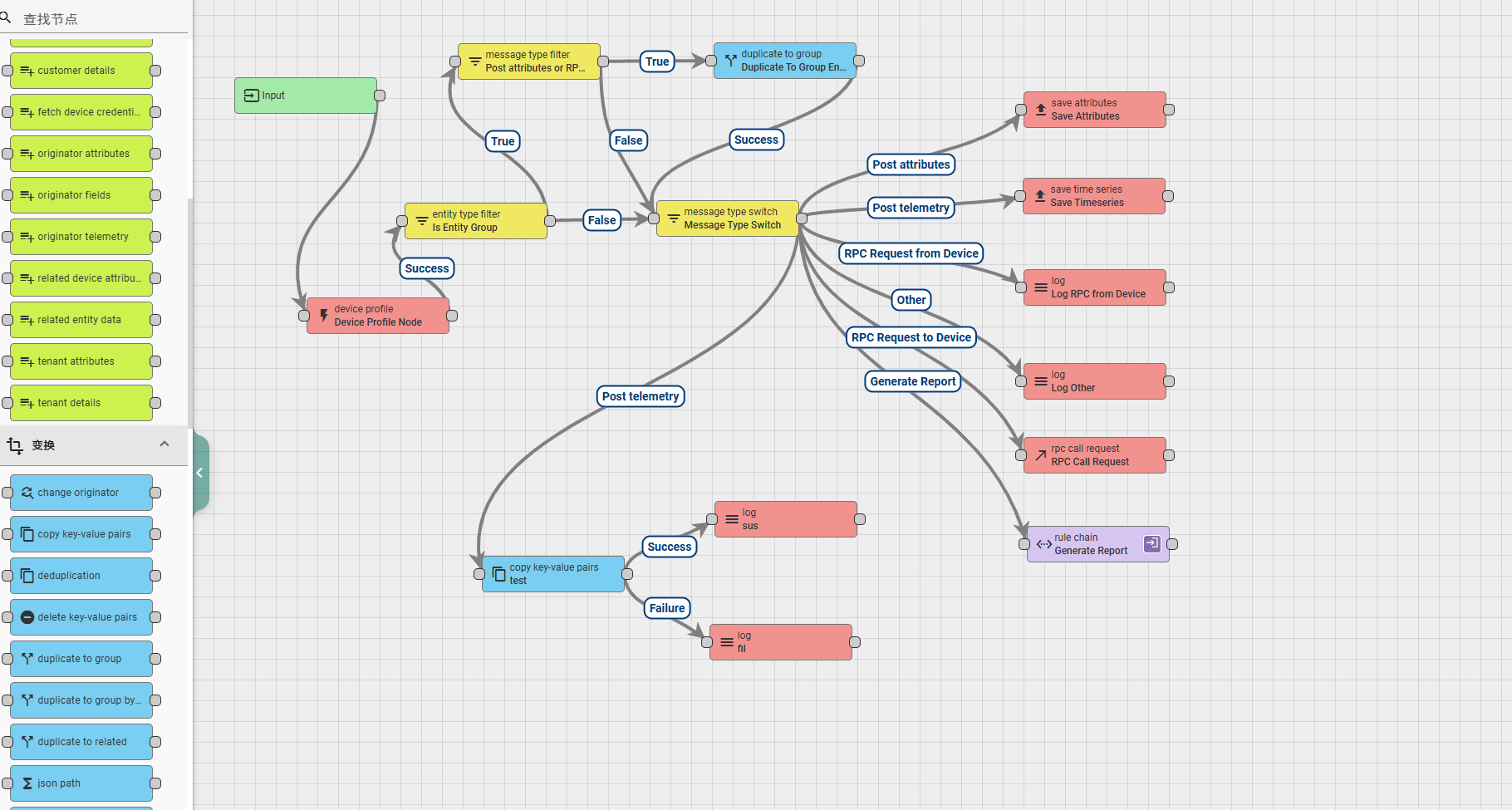
6.3.2 delete key-value pairs
This node is used to delete key values in data or metadata. The node configuration includes:
Name: required field, indicating the name of the node;
Delete from: Select an option that allows you to choose where to delete data, from the data, or from the metadata.
The following input boxes allow you to enter the name of the attribute to be copied, and you can enter multiple names. After entering, press Enter to complete the typing once;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
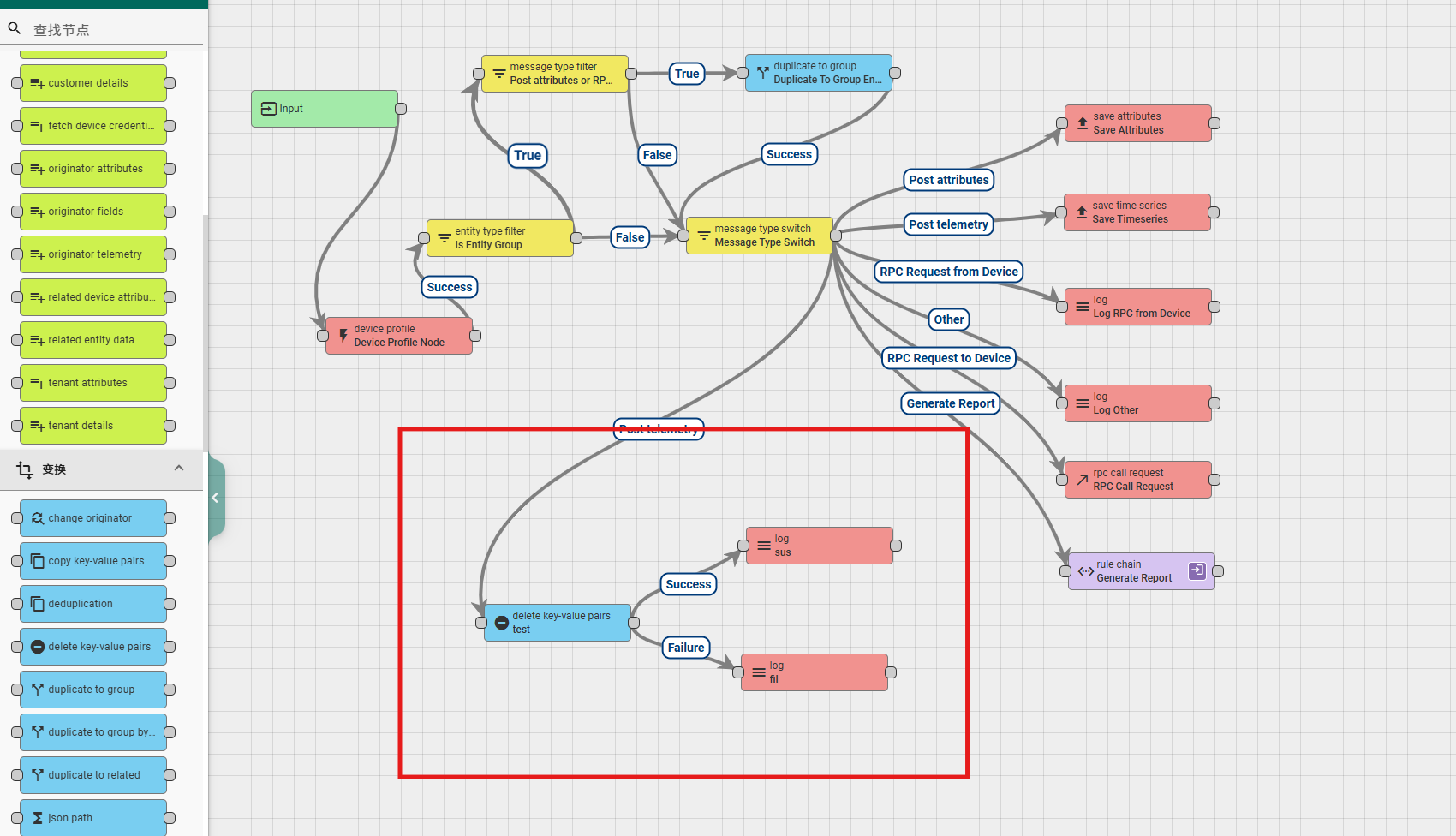
6.3.3 rename keys
This node is used to rename attributes in data or metadata. The node configuration includes:
Name: required field, indicating the name of the node;
Rename keys in: a selection option that allows you to choose where to change the data, either from the data or from the metadata.
The following Key name and New Key name appear in pairs, indicating the original attribute name and the new attribute name;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
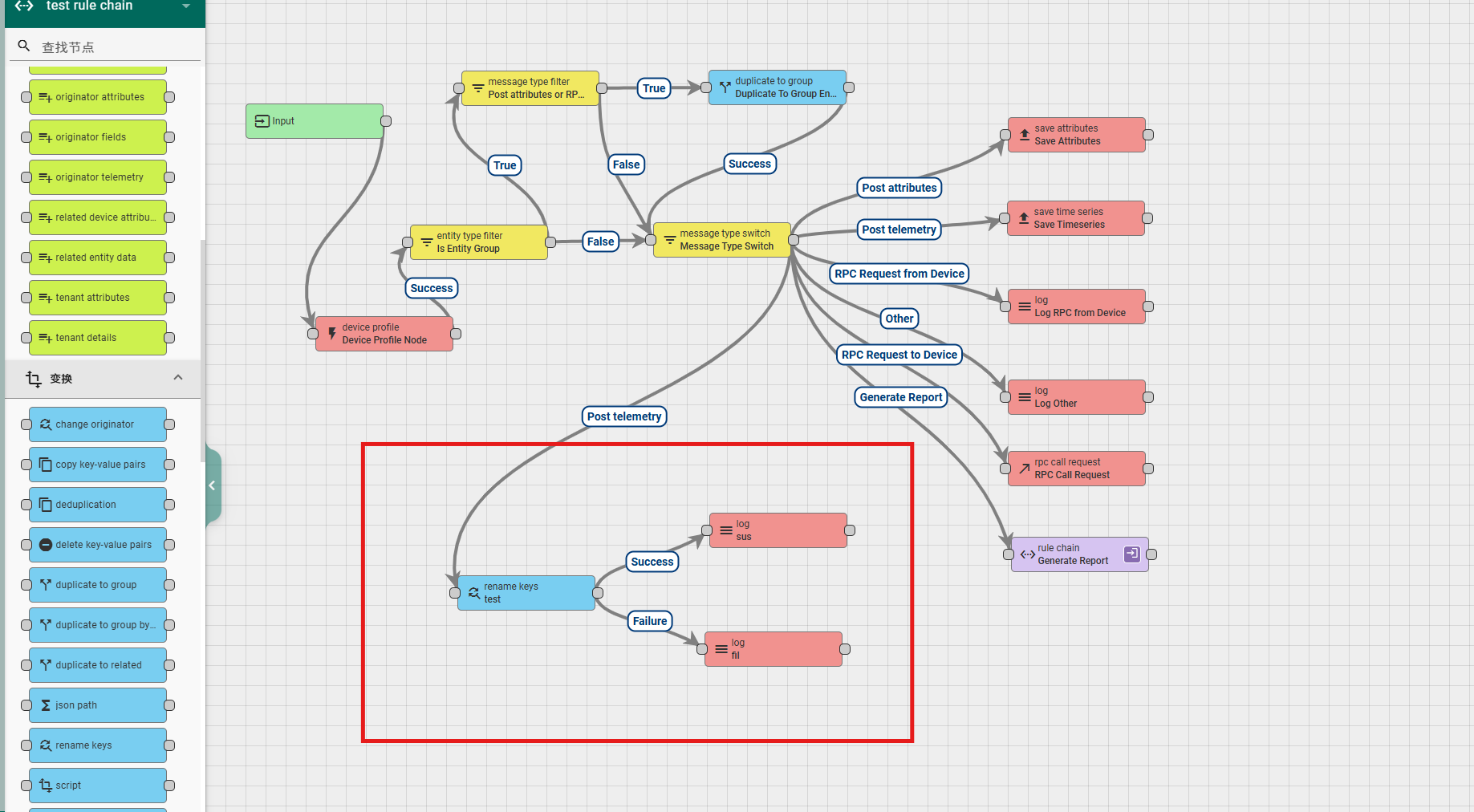
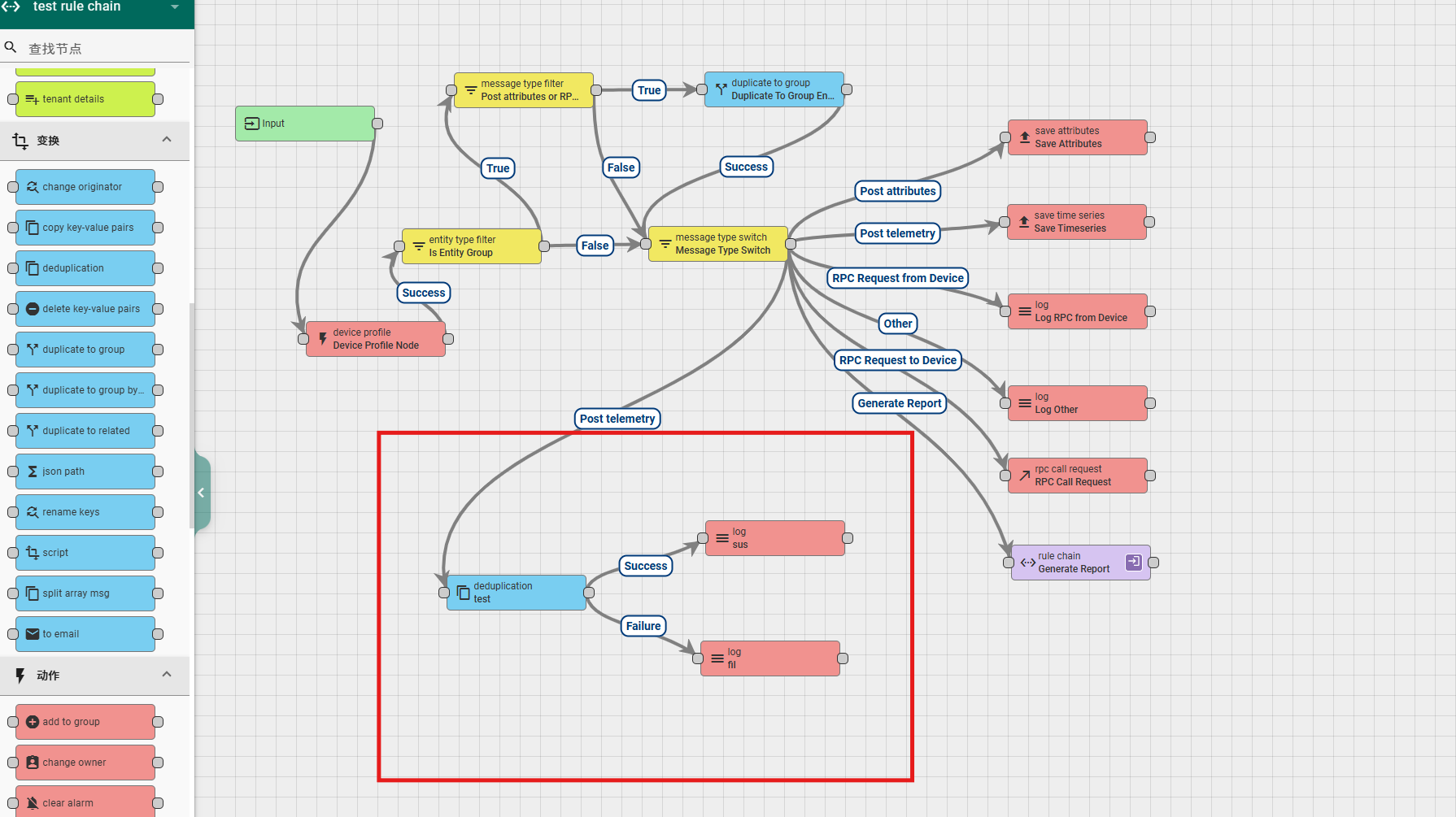
6.3.4 deduplication
This node can be used for message deduplication or changing the frequency of sending messages downstream. The configuration content of the node includes:
Name: required field, indicating the name of the node;
Interval: required field, indicating the time interval, that is, how often data is sent downstream;
Strategy: Select option, indicating the strategy for sending messages downstream. The system provides three strategies for developers to choose from, namely First Message, Last Message, and All Messages. The first two strategies are to send the earliest or latest data downstream, and the last strategy is to send a JSON string group of all data. When selecting the latter left strategy, it is also necessary to configure the Output message type and queue. The former is for message type configuration, while the latter is for queue configuration;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
When selecting the All Messages mode, the data format received by downstream nodes is as follows:
"msg": {
"temperature": 26,
"humidity": 31
},
"metadata": {
"deviceType": "default",
"deviceName": "device-01",
"ts": "1703490713006"
}
}, {
"msg": {
"temperature": 12,
"humidity": 16
},
"metadata": {
"deviceType": "default",
"deviceName": "device-01",
"ts": "1703490718019"
}
}, {
"msg": {
"temperature": 15,
"humidity": 16
},
"metadata": {
"deviceType": "default",
"deviceName": "device-01",
"ts": "1703490723041"
}
}, {
"msg": {
"temperature": 13,
"humidity": 10
},
"metadata": {
"deviceType": "default",
"deviceName": "device-01",
"ts": "1703490728061"
}
}, {
"msg": {
"temperature": 12,
"humidity": 18
},
"metadata": {
"deviceType": "default",
"deviceName": "device-01",
"ts": "1703490733073"
}
}]
6.3.5 script
This node allows developers to customize data transformations through code, and can modify the content and format of data sent downstream through code logic. The node configuration content is as follows:
Name: required field, indicating the name of the node;
Function Transform: Code (customizing transformation rules through code), the input parameters of the function include msg (message), metadata (metadata), msgType (message type pushed by the previous node), and the return value should be in a fixed format {msg: newMSG, metadata: newMetadata, msgType: newMgType}, where the value is the object we have changed;
Explanation: Non mandatory field, additional explanation;
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
Transform logical code:
msg.timestamp = metadata.ts;
msg.province = 'GUANGDONG';
msg.city = 'SHENGZHENG';
return {
msg: msg,
metadata: metadata,
msgType: msgType
};
Data received by downstream nodes:
"temperature": 21,
"humidity": 15,
"timestamp": "1703491991280",
"province": "GUANGDONG",
"city": "SHENGZHENG"
}
Example usage:
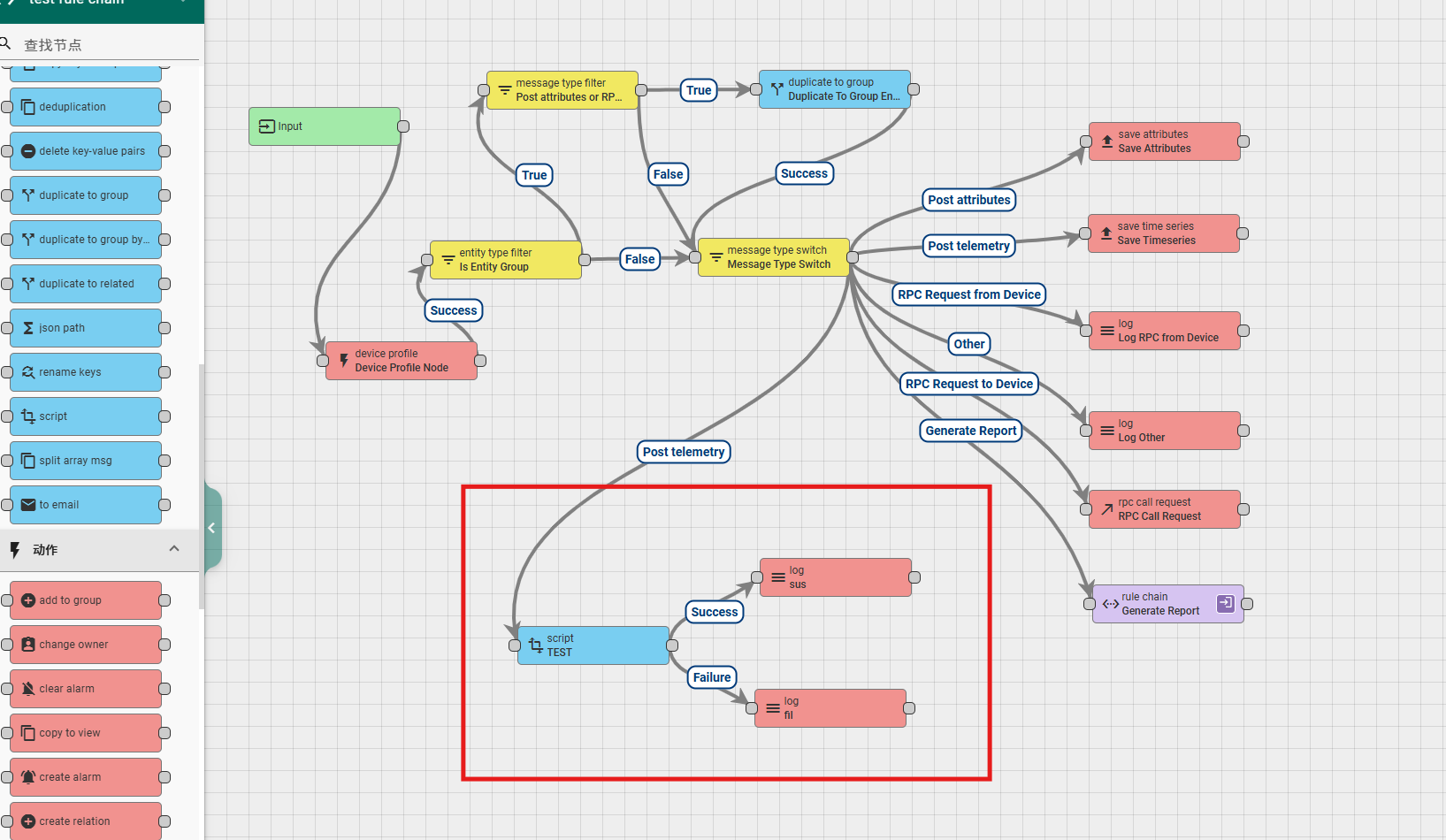
6.4 action
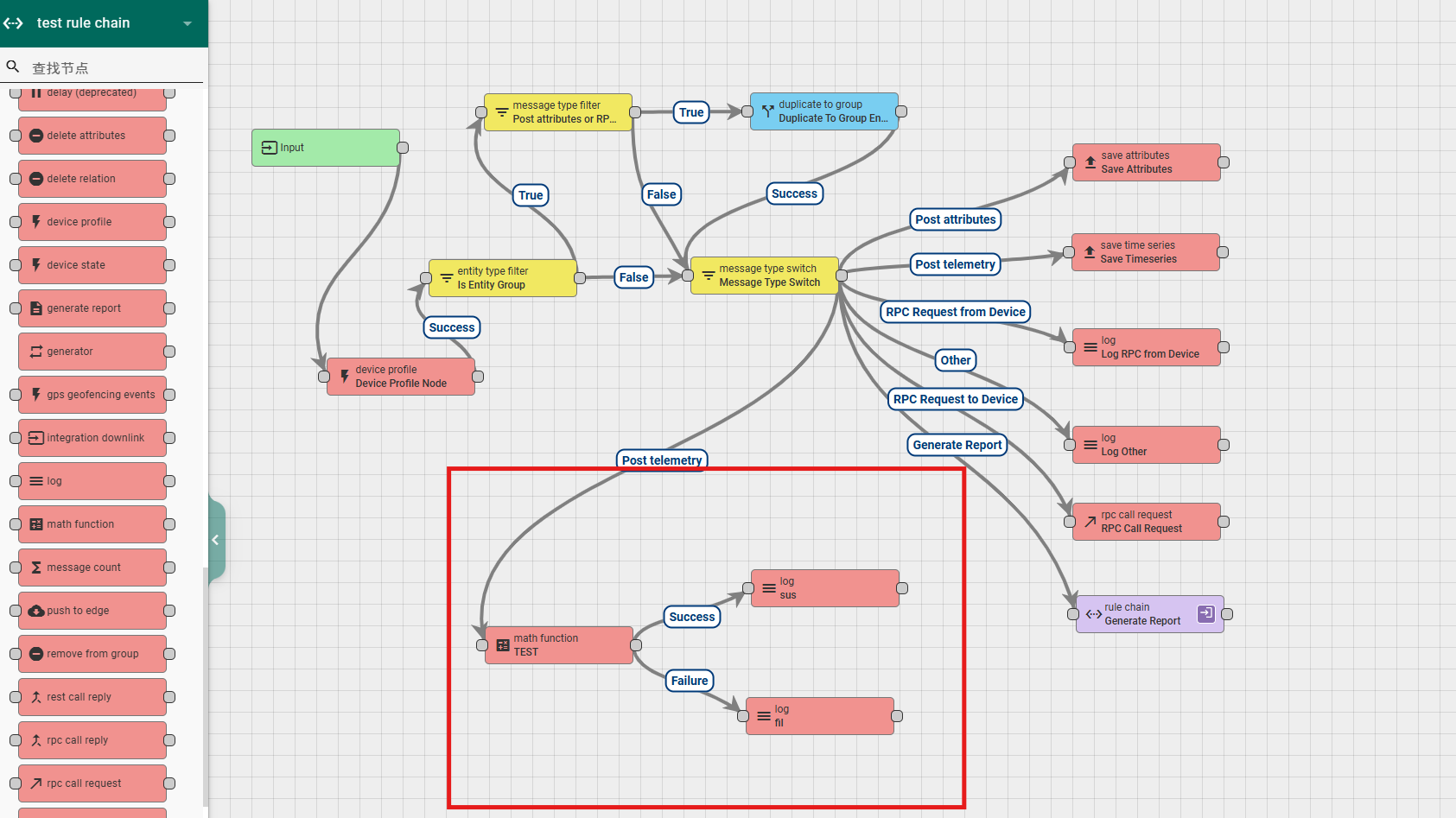
6.4.1 math function
This rule node can perform mathematical calculations and save the results to messages or databases. The configurable contents of this node include:
Name: required field, indicating the name of the node;
Functions: Mathematical functions, the system provides many commonly used mathematical functions for users to use (see table below). In addition, users can choose Custom Function to customize the function;
Arguments: Set the mapping relationship between the parameters in the function formula and the actual physical quantity. Multiple mapping relationships can be added here. Type is a mapping relationship type, and the system provides 5 mapping relationship types to choose from, namely:
- Attribute: Select from the attributes, where the Key in the configuration is the attribute name, the Attribute scope is the scope of the attribute (shared attribute, client attribute, server attribute), and the Default value is the missing default value;
- Time series: Select from the time series data, where the Key in the configuration is the attribute name of the time series data, and the Default value is the missing default value;
- Constant: The Constant value in its configuration is the value of the constant;
- Message body: Select from the message body, where the Key in its configuration is the property name in the message body, and the Default value is the missing default value;
- Message metadata: Select from the message metadata, where the Key in the configuration is the attribute name in the message metadata, and the Default value is the missing default value;
Mathematical Expression: When selecting a custom function, this option needs to be configured to set the calculation rules for the function. The parameters in the formula need to be represented using mappings such as x, y, z in Arguments.
Result: Used to configure how to use the results of function calculations. The system provides four options for selection, namely:
- Attribute: configured into an attribute and can be stored as an attribute in the database. The Attribute scope in its configuration is used to set the scope of the attribute, which can be selected from shared attributes and server attributes. The Key is used to configure the name of the attribute, the Number of digits after floating point is used to configure the reserved decimal places of the calculation result, and the Add to message body and Add to message metadata are optional options. After checking, the data will be synchronously stored in the message body and metadata;
- Time series: configured into time series data and can be stored as time series data in the database. Key is used to configure the name of the attribute, Number of digits after floating point is used to configure the reserved decimal places of the calculation result, and Add to message body and Add to message metadata are optional options. After checking, the data will be synchronously stored in the message body and metadata;
- Message body: configured into the message body and can be passed as message content to downstream rule nodes. Key is used to configure the name of the attribute, and Number of digits after floating point is used to configure the reserved decimal places of the calculation result;
- Message metadata: configured into the message metadata and can be passed as message metadata to downstream rule nodes. Key is used to configure the name of the attribute, and Number of digits after floating point is used to configure the reserved decimal places of the calculation result;
Explanation: Non mandatory field, additional explanation;
The built-in functions of the system are shown in the following table:
| function | Number of parameters | refer to | |
| ADD | 2 | x + y | |
| SUB | 2 | x - y | |
MULT | 2 | x * y | |
| DIV | 2 | x / y | |
| SIN | 1 | Returns Triangular Sine | |
| SINH | 1 | Returns hyperbolic sine (ex-e-x)/2 | |
| COS | 1 | Returns Triangular Cosine | |
| COSH | 1 | Returns Triangular Cosine (ex+e-x)/2 | |
| TAN | 1 | Returns Triangular Tangent | |
| TANH | 1 | Returns hyperbolic tangent | |
| ACOS | 1 | Returns within the inverse cosine range of 0.0 to pi | |
| ASIN | 1 | Returns within the sine arc range of * pi/2 to pi/2* | |
| ATAN | 1 | Returns are cut within the range of pi/2 to pi/2 | |
| ATAN2 | 2 | Returns rectangular coordinates | |
| EXP | 1 | Returns ex | |
| EXPM1 | 1 | Returns ex-1 | |
| SQRT | 1 | Returns positive square root | |
| CBRT | 1 | Returns multidimensional dataset root | |
| GET_EXP | 1 | Returns unbiased index | |
| HYPOT | 2 | Returns unbiased index sqrt (x2+y2) | |
| LOG | 1 | Returns Natural Logarithms | |
| LOG10 | 1 | Returns 10 logarithms | |
| LOG1P | 1 | The natural logarithm of the sum of the Returns parameter and 1 | |
| GEIL | 1 | Returns minimum integer | |
| FLOOR | 1 | Returns maximum integer | |
| FLOOR_DIV | 2 | Maximum quotient of Returns | |
| FLOOR_MOD | 2 | Returns base modulus | |
| ABS | 1 | Returns Absolute Value | |
| MIN | 2 | Minimum Returns | |
| MAX | 2 | Maximum Returns | |
| POW | 2 | Returns power | |
| SIGNUM | 1 | Returns symbol function | |
| RAD | 1 | Convert angles measured in degrees to approximately equivalent angles measured in radians | |
| DEG | 1 | Convert the angle measured in radians to an approximate equivalent angle measured in degrees | |
| CUSTOM | 1-16 | Custom functions such as (x-32)/1.8 use this function to specify complex mathematical expressions |
According to the running results, there are two types of exits for this rule node: Success and Failure.
A simple usage example is as follows:
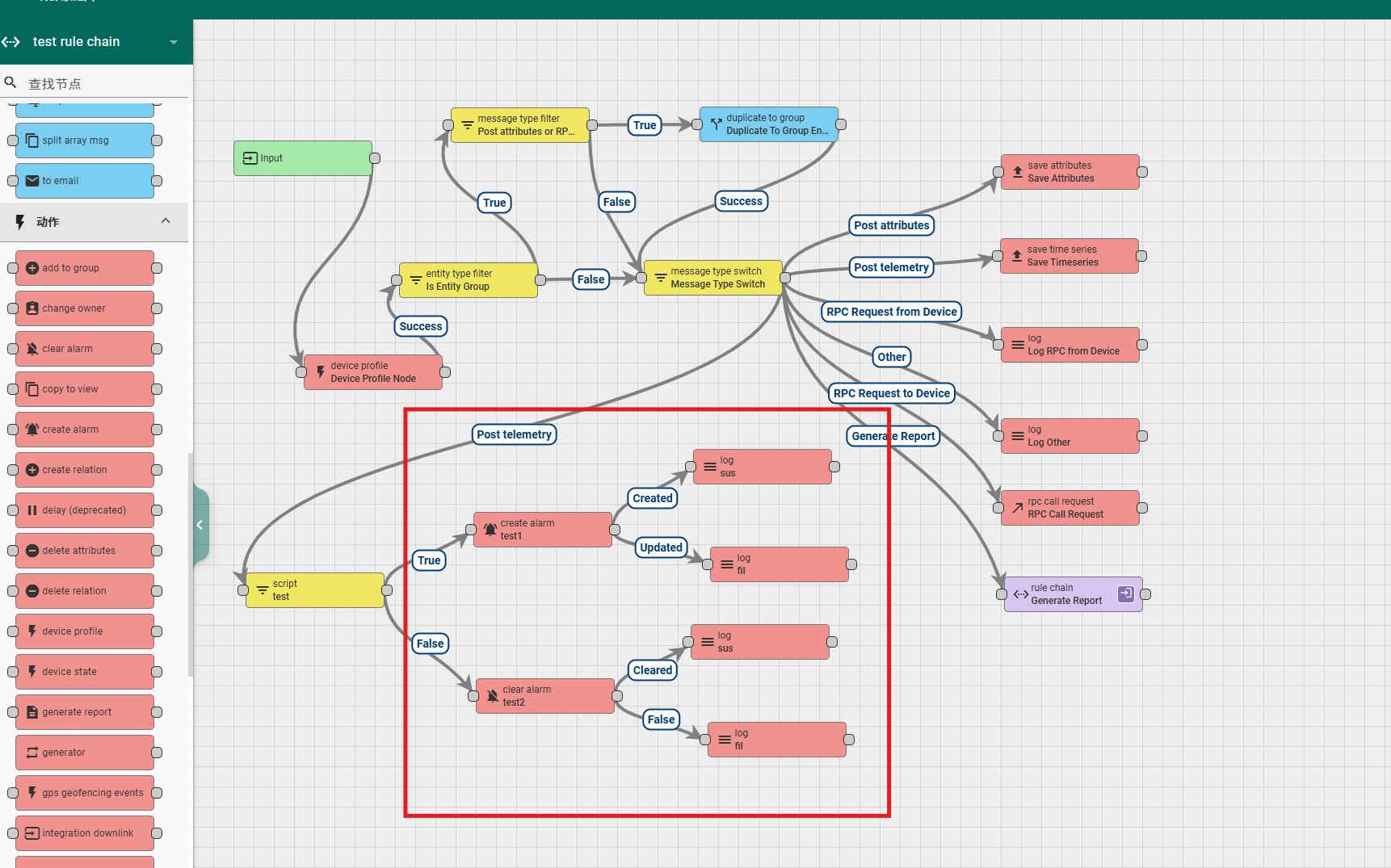
6.4.2 create alarm && clear alarm
Two rule nodes are used to create and clear alerts, respectively. As long as there is data flowing into the node that creates or clears alerts, an alert will definitely be created or cleared. Nodes can customize the detailed content of alerts through encoding. In this system, there can be at most one alarm message of the same type for the same device, and subsequent alarms will be presented in an updated manner. When existing alarms are cleared, subsequent alarm information will be created.
The contents that need to be configured for the create alarm rule node are:
Name: required field, indicating the name of the node;
Function Details: Define the detailed content of the alert. The function parameters include msg (message), metadata (metadata), and msgType (message type pushed by the previous node). The previous alert details can be accessed through metadata. prvAlarmDetails. The return value should be the details object, which is the detailed information of the alarm;
Alarm type: required field, customizable alarm type;
Alarm severity: required option, configure the degree of danger of the alarm, the system provides five levels of danger, important, secondary, warning, and uncertain for selection;
Explanation: Non mandatory field, additional explanation;
According to the running results, the exits of this rule node include Created, Updated, False, and Failure. Newly created alerts will be passed through the Created exit, while updated alerts will be passed through the Updated exit.
The clear alarm rule node needs to configure the following contents:
Name: required field, indicating the name of the node;
Function Details: Define the detailed content of the alert. The function parameters include msg (message), metadata (metadata), and msgType (message type pushed by the previous node). The previous alert details can be accessed through metadata. prvAlarmDetails. The return value should be the details object, which is the detailed information of the alarm;
Alarm type: required field, customizable alarm type;
Explanation: Non mandatory field, additional explanation;
According to the running results, the exits of this rule node are Cleared, False, and Failure. Cleared alerts will be passed through the Cleared exit, and alerts that do not need to be cleared will be passed through the False exit.
A simple usage example is as follows. In this example, it is defined that a high temperature alarm is triggered when the temperature is 28 degrees Celsius or above. The alarm content records the current temperature and the number of messages that continuously trigger the high temperature alarm; If the temperature reported by the device is below 29 degrees Celsius, clear the alarm.
Create alarm rule node code:
if (metadata.prevAlarmDetails) {
var prevDetails = JSON.parse(metadata.prevAlarmDetails);
if(prevDetails.count) {
details.count = prevDetails.count + 1;
}
}
return details;
Clear alarm rule node code:
if (metadata.prevAlarmDetails) {
details = JSON.parse(metadata.prevAlarmDetails);
//remove prevAlarmDetails from metadata
delete metadata.prevAlarmDetails;
//now metadata is the same as it comes IN this rule node
}
return details;
Rule chain configuration:
6.4.3 delay
This rule node is used to delay the data flowing into the node for a certain period of time before sending it out to downstream nodes. Its configuration includes:
Name: required field, indicating the name of the node;
Use period in seconds pattern: optional, when checked, you can use the value of certain attributes in the message body or metadata as the delay time for the message, which is not checked by default;
Period in seconds: required field, used to configure delay time;
Period in seconds pattern: Required field, used to specify which attribute value to use as the delay time when 'Use period in seconds pattern' is checked. Use ${metadataKey} to retrieve the numerical values in the metadata, and use $[messageKey] to retrieve the numerical values in the message body;
Maximum pending messages: Used to specify the length of the node queue. Data flowing into the node will be placed in a pending queue, and after a delay time, the data will be sent downstream and deleted from the queue;
Explanation: Non mandatory field, additional explanation;
According to the queue size, this rule node has two exits, Success and Failure. The data that is suspended in the queue and reaches the delay time will flow out from the Success exit, and the data that reaches the node after the queue is full will flow out from the Failure exit.
A simple usage example is as follows:
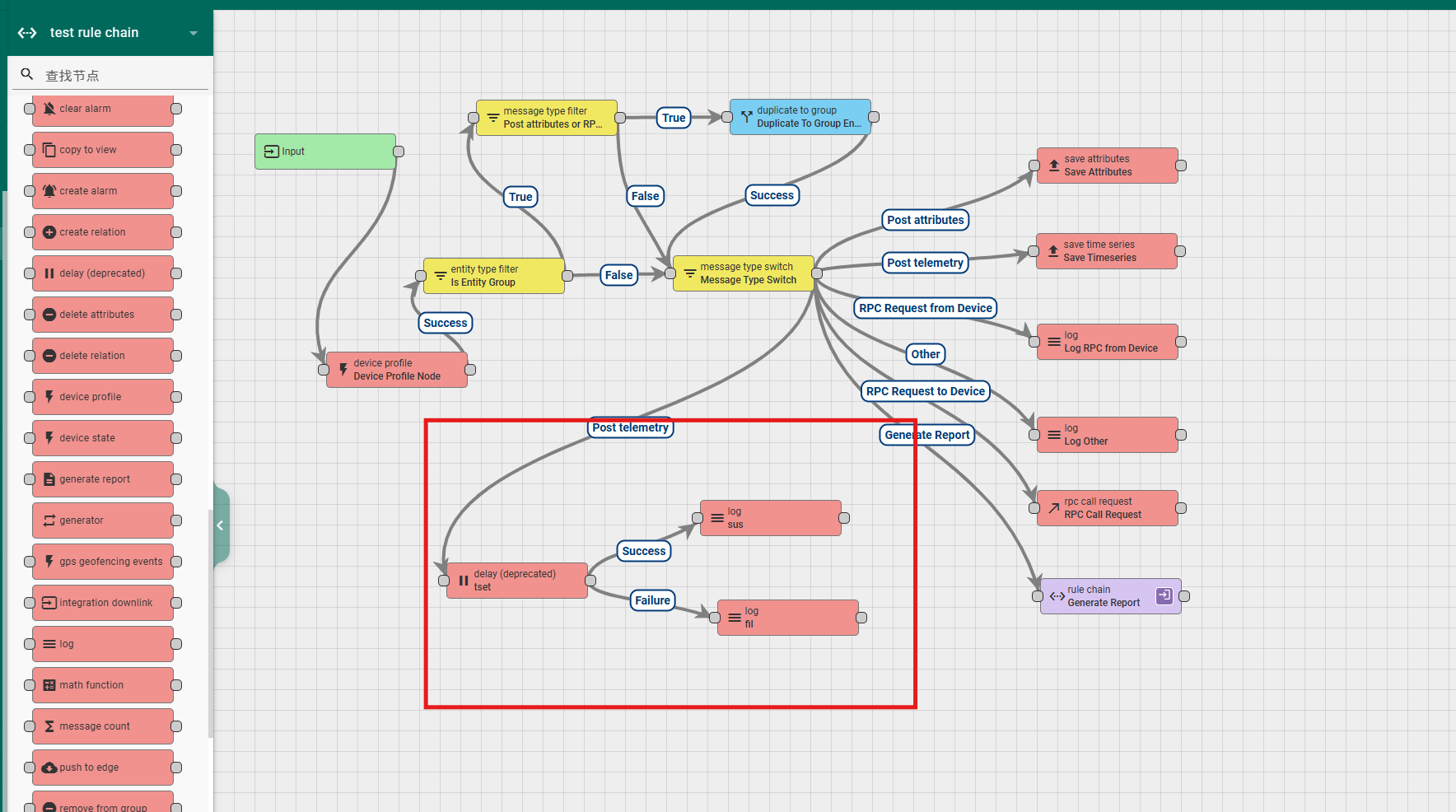
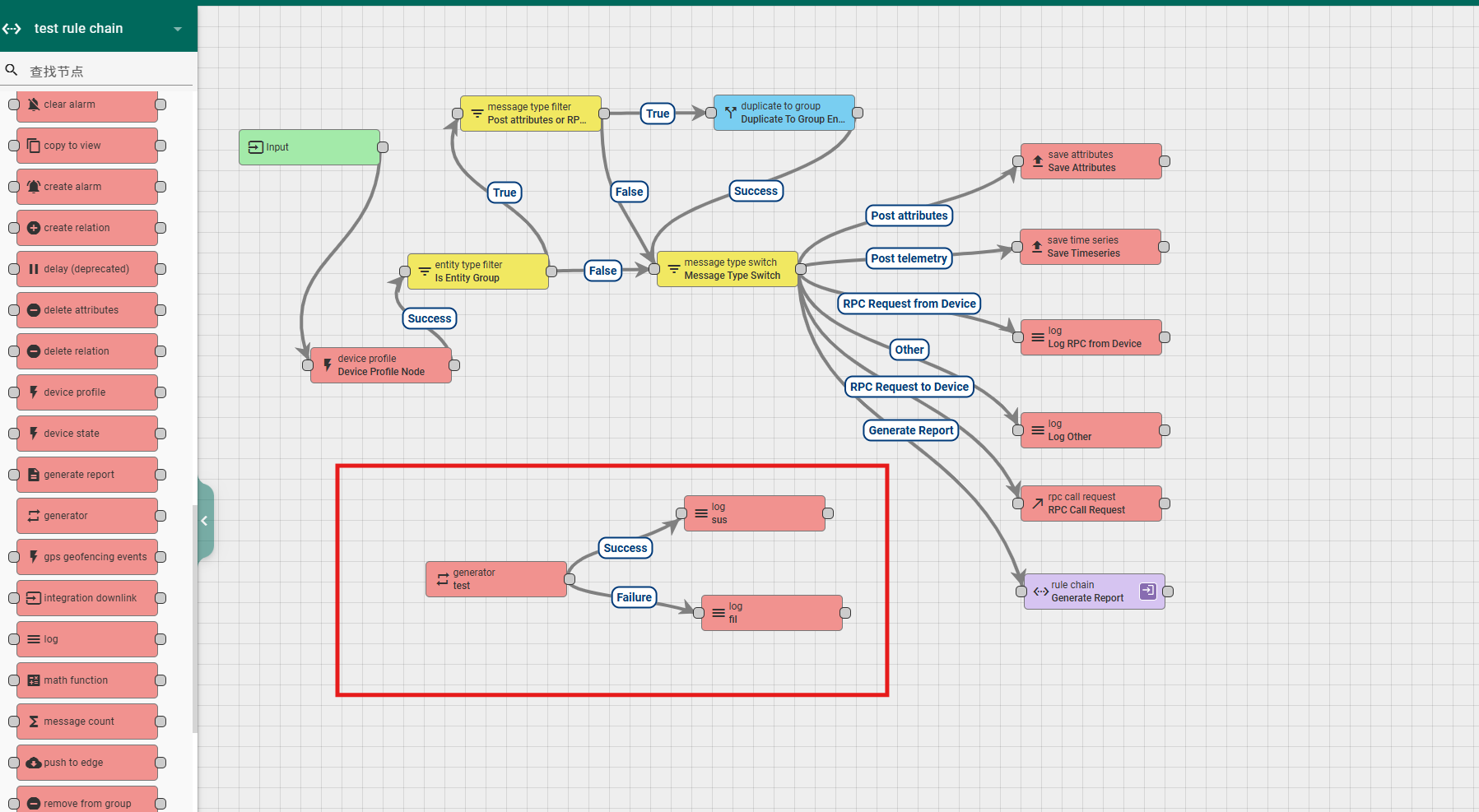
6.4.4 generator
This node is used to generate messages and is typically used for testing rule chains during development. Its configuration includes:
Name: required field, indicating the name of the node;
Message count: required field, configure the number of messages produced;
Period in seconds: required field, configure the time interval for message sending;
Type: Non mandatory field, can specify the initiating entity of the message;
Queue: Non mandatory field, can specify the sending strategy of the message;
Function Generate: The generated message content and format can be defined through encoding. The input parameters of the function include pre message body (previous message body), pre message metadata (previous message metadata), and pre message type (previous message type). The return value of the function should be in the format of {msg: msg, metadata: metadata, msgType: msgType}, where the values msg, metadata, and msgType are all objects;
Explanation: Non mandatory field, additional explanation;
According to the execution status, the rule node has two exits, Success and Failure.
A simple usage example is as follows:
6.4.5 log
This node is used to encode the outgoing message into a string and record it in the system's log file. Its configurable contents include:
Name: required field, indicating the name of the node;
Function AKS String: The format of logging can be defined through encoding. The input parameters of the function include msg (message body), metadata (message metadata), msgType (message type), and the return value of the function should be a string type;
Explanation: Non mandatory field, additional explanation;
According to the execution status, the rule node has two exits, Success and Failure.
6.5 external
6.5.1 kafka
This node can forward the message body of incoming messages to Kafka, essentially configuring a Kafka producer client. The configurable contents include:
Name: required field, indicating the name of the node;
Topic pattern: required field, specify the topic of message sending, use ${metadataKey} to obtain the value of the corresponding attribute in the metadata as the topic, and use $[messageKey] to obtain the value of the corresponding attribute in the message body as the topic;
Key pattern: Non mandatory field, used to specify the Key of the message. Messages with the same Key will be assigned to the same partition;
Bootstrap servers: required field, specify the address of Kafka service;
Automatically retry times if failures: Non mandatory field, used to specify the number of retries when message sending fails, default is 0;
Produce batch size: Non mandatory field, used to specify the batch size in bytes, default is 16384;
Time to buffer locally: Non mandatory field, used to specify the maximum duration of the local buffer window, default is 0;
Client buffer max size: Non mandatory field, used to specify the maximum buffer size (in bytes) for sending messages, default is 33554432;
Number of acknowledgments: Required field, used to specify how many replicas in the partition receive the message, and the producer considers the message to have been successfully written. Setting it to 0 can ensure maximum throughput; Setting acks to -1 or all ensures the strongest reliability; A compromise solution between message reliability and throughput when tasks are set to 1;
Key serializer: required field, default is org.apache.kafka.common.serialization StringSerializer;
Value serializer: required field, default is org.apache.kafka.common.serialization StringSerializer;
Other properties: Any other properties can be provided for Kafka client connections, added in the form of key value pairs, and multiple pairs can be added;
Add Message metadata key value pairs to Kafka record headers: optional. When checked, the metadata of the message will be added to the headers of the Kafka client connection in the form of key value pairs;
Explanation: Non mandatory field, additional explanation;
According to the forwarding situation, the rule node has two exits, Success and Failure.
A simple configuration example is as follows:


6.5.2 mqtt
This node can forward the message body of incoming messages to the Mqtt server. Its configurable contents include:
Name: required field, indicating the name of the node;
Topic pattern: required field, used to configure the topic, can be a static string, or can use message metadata properties through ${DeviceType};
Host: required field, used to configure the Mqtt proxy server address;
Port: required field, used to configure the Mqtt proxy server port, default is 1883;
Connection timeout: required field, used to configure the timeout period (in seconds) for connecting to the Mqtt server, default is 10;
Client ID: Non mandatory field, used to configure the client ID. If not specified, the default generated client ID will be used;
Add Service ID as suffix to Client ID: optional, can only be checked after configuring the Client ID. Checking it will add the Service ID as a suffix to the Client ID;
Clean session: optional, configurable whether to delete session, checked by default;
Retained: optional, configurable whether to keep the message, not checked by default;
Enable SSL: optional, used to enable/disable secure communication, not checked by default;
Credentials: Mqtt connection credentials. The system provides three connection credential verification methods, namely Anonymous (unverified), Basic (username and password verification), and PEM (credential file verification);
Explanation: Non mandatory field, additional explanation;
According to the forwarding situation, the rule node has two exits, Success and Failure.
A simple configuration example is as follows:
